Stop giving your agents database credentials
AI agents don’t fail in production because they lack autonomy. They fail because autonomy without structure is impossible to trust.

A number came up at Data + AI Summit this week that validated something we've been saying at CrewAI for a long time:
The agent loop, the reasoning, the tool calling, the clever prompting, is roughly 1% of the work.
The other 99% is building, configuring, deploying, securing, evaluating, and monitoring.
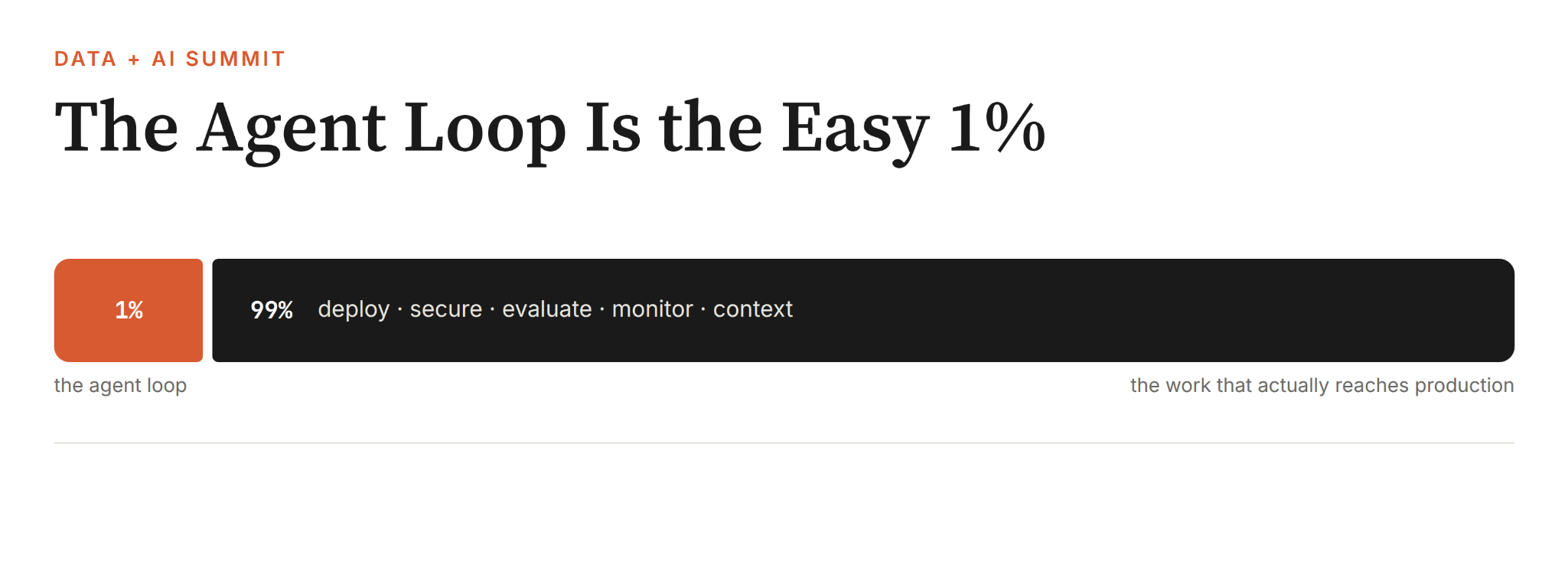
I was on a founders' panel at Summit called "The Agentic Stack," and that 99% was the actual conversation. Not which model is smartest, nor which framework wins but the actual infrastructure between "this demo is cool" and "this runs in production and the business trusts it."
Companies nowadays have 20, 100, sometimes 800 agentic use cases identified, but their AI team can realistically deliver maybe 10 this year.
The bottleneck isn't agent logic though, it's usually a mix of things like governance, control, ability to federate the building, the data access model, and sometimes the data itself. Not just who can access what, but whether the data is structured and labeled well enough for an agent to use it responsibly.
The prototype works because someone gave it broad access to a dev database with clean sample data, then the security review happens, and oh boy, then the data governance team shows up, and now the project sits for three months while everyone argues about access controls, data quality, and semantic definitions that should have been sorted from the start.
For this post I wanna focus on the data related problems and the first one is the mistake of treating "give the agent data access" as one problem. It's not. It's at least four different problems, and each one needs a different kind of interaction.
The four conversations agents have with data
Think about how a senior analyst actually works inside a company, they don't do one thing with data, but they might do several, depending on what they need.
Sometimes they ask a business question in plain language and want an answer that uses the company's actual definitions, like what counts as revenue or which customers are active. They're not writing SQL, they're relying on the semantic layer to get it right.
Sometimes they write a precise query because they know exactly what they need. They just need a specific table, the right columns, the right filters and need the warehouse to execute it and return rows.
Sometimes they call an approved function, a calculation or business rule that someone already vetted and registered.
And sometimes they search, they might need to find relevant documents or records across unstructured data, less of a regular DB query with a known schema, more of a retrieval problem.
Four different modes of interacting with data, but each one has its own governance surface, and each one breaks differently when you get the permissions wrong.
When you hand an agent a single database connection, you're collapsing all four into one: raw SQL against whatever the credentials can reach, the agent generates queries against tables it may not understand, with no semantic layer, no function governance, no retrieval optimization. Your data platform's audit trail doesn't even recognize what's happening.
That's before you even get to data quality. The agent doesn't know that the "revenue" column in one table means something different than in another, or that half the records in a legacy table haven't been updated since 2023.
It's the equivalent of giving a new hire the production database password on day one and saying "figure it out."
What the right abstraction looks like
Each of those four interactions should be a separate, governed tool, not one open pipe.
- Ask a business question through a semantic layer. The agent asks what it needs in plain language, and the semantic layer translates it using business definitions that already exist. The agent gets answers grounded in what the company actually means by "revenue" or "active customer." The meaning lives in the catalog, not scattered across prompts.
- Run a governed query. When the agent needs specific data, it goes through a warehouse with the same permissions any human analyst would have. Row-level security, column masking, audit logs, all enforced by the data platform.
- Call registered business logic. Approved calculations and transformations, published as callable tools. The agent invokes them by name instead of reimplementing business logic in a prompt.
- Search governed indexes. When the agent needs unstructured data, it hits a vector index that was built and governed within the data platform.
This is what we just shipped in CrewAI AMP
We added Databricks as a managed integration in CrewAI AMP.
Four managed MCP servers, one for each interaction pattern:
- Genie for natural-language questions over governed semantic models
- Databricks SQL for query execution through governed warehouses
- Unity Catalog Functions for calling registered business logic
- Vector Search for retrieval over Mosaic AI Vector Search indexes
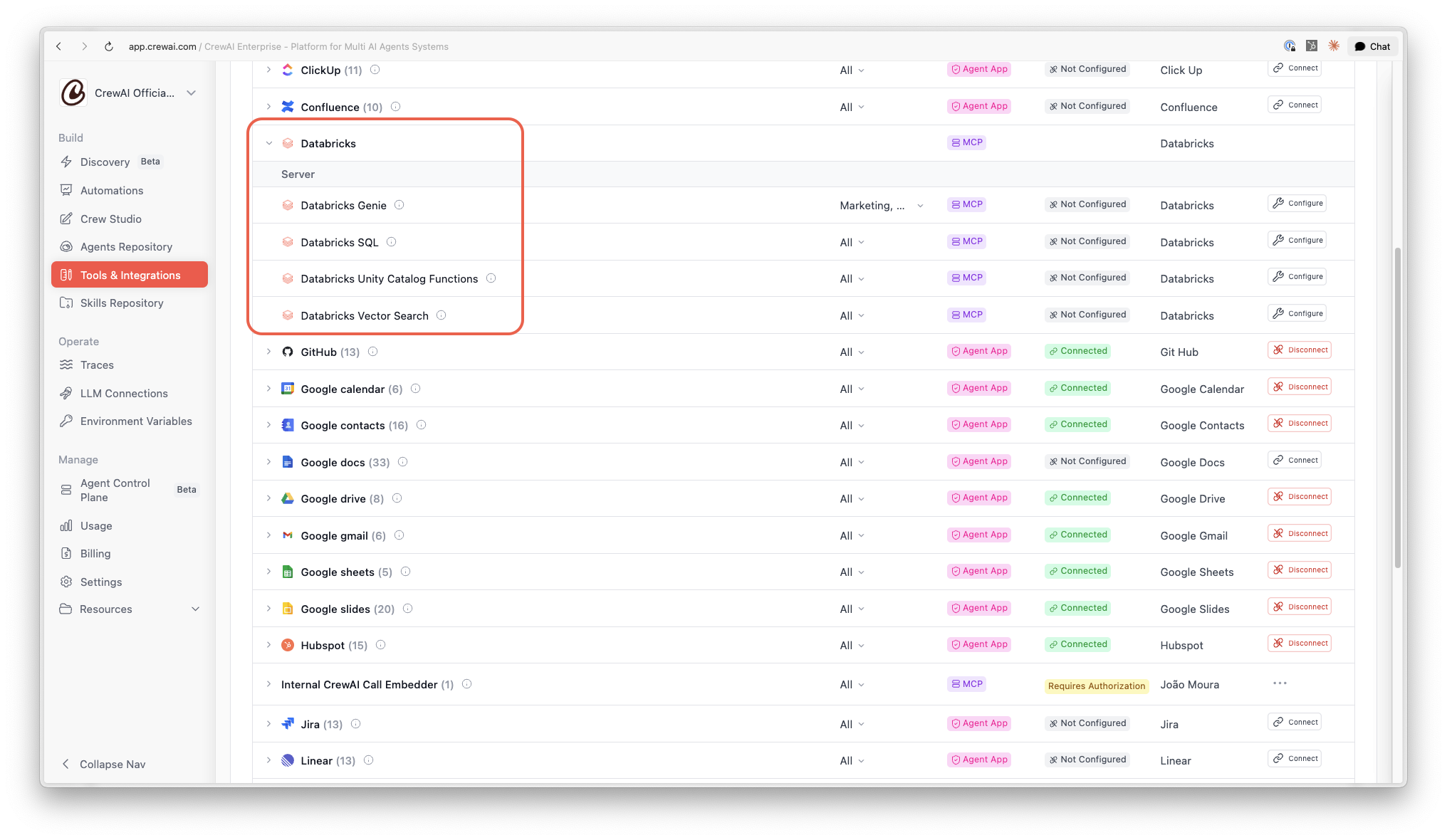
Each one is configured independently, so a crew or flow that does financial analysis might use Genie and SQL, while another crew that handles support escalations might use Vector Search and UC Functions. You enable what the workflow needs, nothing more.
For developers who want direct SQL access in code, DatabricksQueryTool in crewai-tools gives you that with sensible defaults: configurable catalog, schema, warehouse, and a row limit so an agent loop doesn't accidentally pull your entire customer table.
The principle
The agent should go through the same governance layer your analysts go through.
If a human analyst at your company can't query a table, the agent acting on their behalf shouldn't be able to either, and if there's an approved function for calculating churn, the agent should call that function instead of generating its own version from a prompt.
This isn't a Databricks-specific insight. It's how agent-data integration should work everywhere. We just made this extremely easier for companies that happen to be Databricks customers as well.
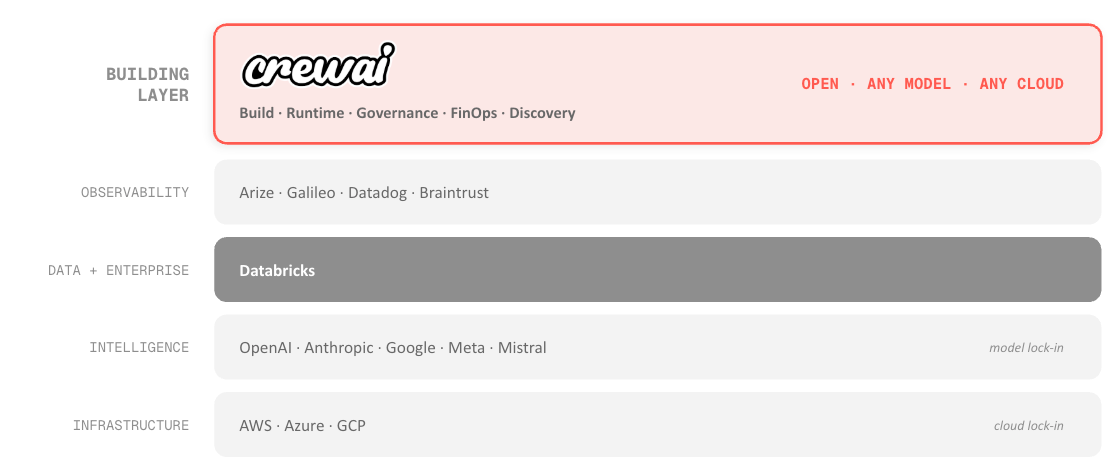
We did the same thing with Snowflake last week. We'll keep doing it with every major data platform, because this is the pattern: agents operating within the enterprise's existing governance boundary, not building a parallel one.
Stop giving your agents database credentials.
Give them governed tools instead.
Comments ()