How we built Cognitive Memory for Agentic Systems

Many agentic systems start every run from zero, the system and its agents discover the same context, calls the same tools, makes the same mistakes, every. single. time. That's not just inefficient, it creates a major ceiling on what agentic systems can do.
The obvious fix is to bolt on some sort of memory into the system, store everything, retrieve by similarity with vectors, hope for the best.
But naive memory implementations creates its own problems like context bloats, outdated information poisoning new executions, the agent hallucinates and by the end of it you traded one problem for a worse one.
We lived this, CrewAI processes billions agentic executions and we saw what happens when memory is treated as a storage problem, and we saw what happens when it's not.
So we rebuild our entire memory system from scratch, focused on actually supporting production agentic systems. Not as a database with a search layer but as a cognitive process, one that encodes selectively, resolves its own contradictions, forgets on purpose, and knows when it doesn't know. We had the opportunity to use LanceDB as the database behind this implementation what has also been full of pleasant surprises, from being super easy to setup, fast to run and very much on the edge.
Here's how we built it and how to use it.
Why Naive Memory Makes It Worse
The market's answer to stateless agents has been to bolt on memory as a service, store everything, embed it, retrieve by similarity. Some approaches do this cleanly, others give you a key-value store with namespaces and leave the rest to you.
The more sophisticated options build temporal knowledge graphs that track when facts changed, all impressive infrastructure, but still infrastructure.
The pattern is the same everywhere: memory is treated as a storage and retrieval problem. The developer is responsible for deciding what's worth remembering, how to organize it, when retrieval is confident enough to act on, and what to do when two memories contradict each other. Your agent learns one thing on Monday and another conflicting on Friday. Now it remembers both.
And none of them ask the question that actually matters: is the retrieval confident enough to act on? They all return results but none of them say "I'm not sure, let me look deeper."
This is what happens at scale when you treat memory as data instead of cognition.
Memory Is Cognition, Not Storage
Human memory doesn't work by storing everything and searching by similarity, it encodes selectively, deciding what matters and where it fits, it consolidates, resolving conflicts between what you knew and what you just learned. It retrieves adaptively, sometimes instantly, sometimes by working through what it knows step by step. And it forgets, not by accident, but because forgetting is what keeps memory useful.
If you really think about, memory itself resembles a lot an Agentic System itself and that's the model we followed, CrewAI's new Cognition Memory system is built around five cognitive operations: encode, consolidate, recall, extract, and forget. Each one is an active process, not a passive read or write, so when you store a memory, the system analyzes its content, assigns importance, detects contradictions, and places it in a self-organizing hierarchy. When you retrieve, the system evaluates its own confidence and decides whether to go deeper.
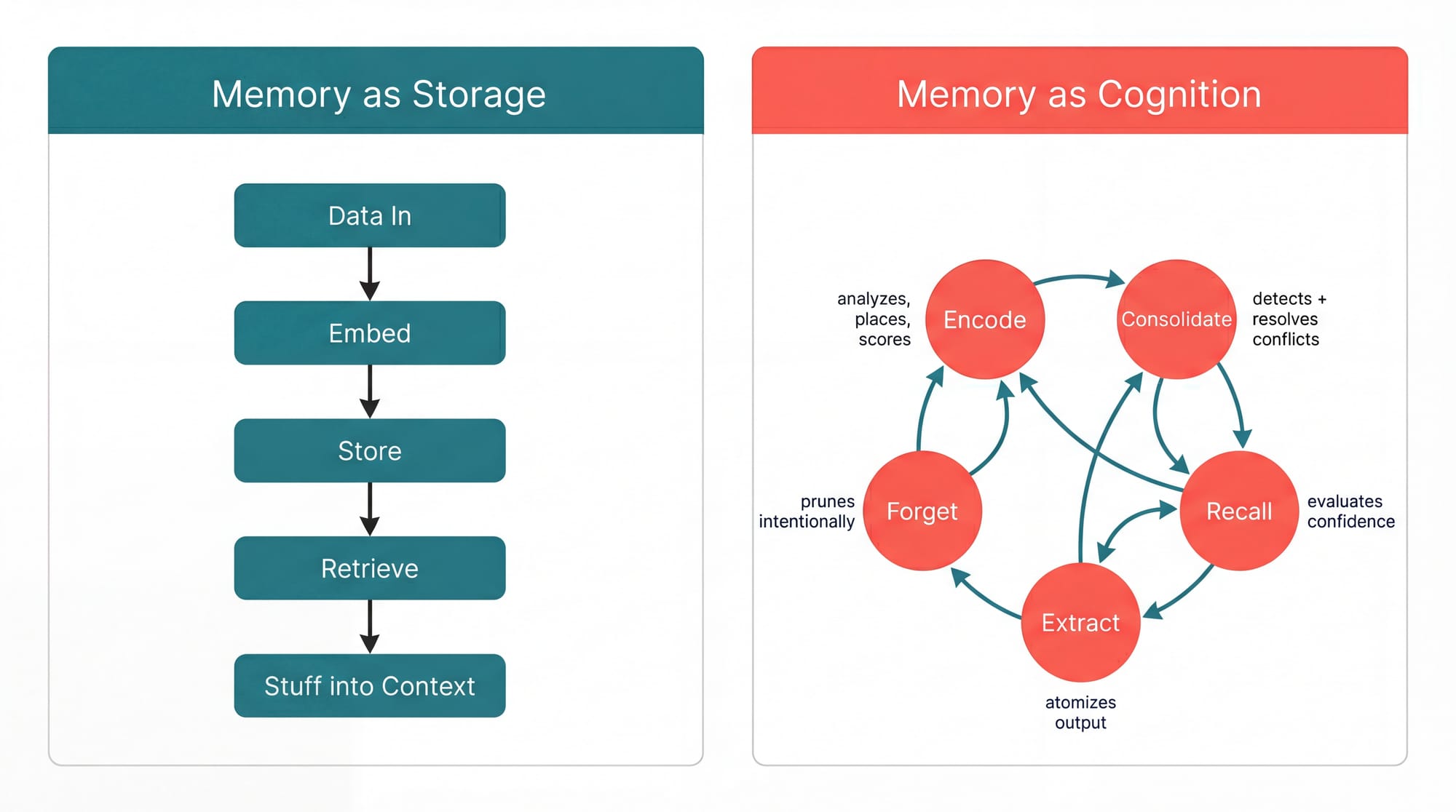
The result is five methods. Here's the full API.
CrewAI's Cognitive Memory
CrewAI's new Cognition Memory is an agentic system on itself that uses CrewAI Flows behind the scenes, full inception. It is available everywhere in your agentic systems:
- You can use it on a single Agent.
- Turn it on in a Crew and all it's agents automatically load and persist memories across tasks, but they can also proactively remember and recall as tools when context matters.
- Use it in a Flow and you get a persistence layer that complements state, where state handles what's ephemeral within a run, memory handles what should compound across runs.
Another cool piece of the implementation bellow is that you can take it with you and have different agent access the same memory while having different setting on how to recall it, by having different weights for the components that go into recalling, like the half life of memories and such.
The native implementation carries an extremely simple DSL implementation, in regular CrewAI fashion, so those five cognitive operations map to five methods:
from crewai.memory import Memory # New Coginitive Memory Class memory = Memory() # Adding new memories directly memory.remember("We decided to use PostgreSQL for the user database.") # Recalling memories directly results = memory.recall("What database are we using?") # Extracting memorable facts from a string facts = memory.extract_memories("Long text with many possible facts") # Getting the memory tree memory.tree() # Forget certain memories from datetime import datetime, timedelta memory.forget(scope="/", older_than=datetime.utcnow() - timedelta(days=30))
Each method triggers its own cognitive pipeline.
remember() doesn't just store, it analyzes what you're saving, detects contradictions against what it already knows, and resolves them.
recall() doesn't just search, it evaluates its own confidence and goes deeper when it's not sure.
The memory system itself is agentic, every operation is a reasoning process, not a read or write.
In a Crew, it's one line:
crew = Crew(
agents=[researcher, analyst],
tasks=[...],
memory=True,
)
Agents load relevant context before each task and persist what they learn after. They can also use remember and recall as tools, the agent itself decides when something is worth storing or when it needs past context. The system handles persistence by default, the agent takes over when it knows better.
In a Flow:
class ResearchFlow(Flow): @start() def research(self): past = self.recall("previous findings on this topic") self.remember(f"Found: {findings}", scope="/research") @listen(research) def analyze(self): context = self.recall("all research findings")
You stop over-engineering state for things that should just be remembered.
Think of state is for what matters right now and memory is for what matters next time.
Now let's look at what's actually happening under the hood.
Under the Memory Hood: Two Cognitive Flows
There are 2 main agentic systems powering this cognitive memory, and Encoding Flow, and a Recall Flow.
Encoding Agentic System
When you call remember(), the CrewAI Flow runs an encoding pipeline that analyzes the content and produces a MemoryAnalysis:
class MemoryAnalysis(BaseModel): scope: str # Where this belongs in the hierarchy categories: list # What this is about importance: float # How much this matters (0-1)
The system decides where a memory belongs, what it's about, and how important it is, all without you specifying anything. No schema designed, the structure actually emerges from the system itself. You can override scope, categories, and importance when you want control.
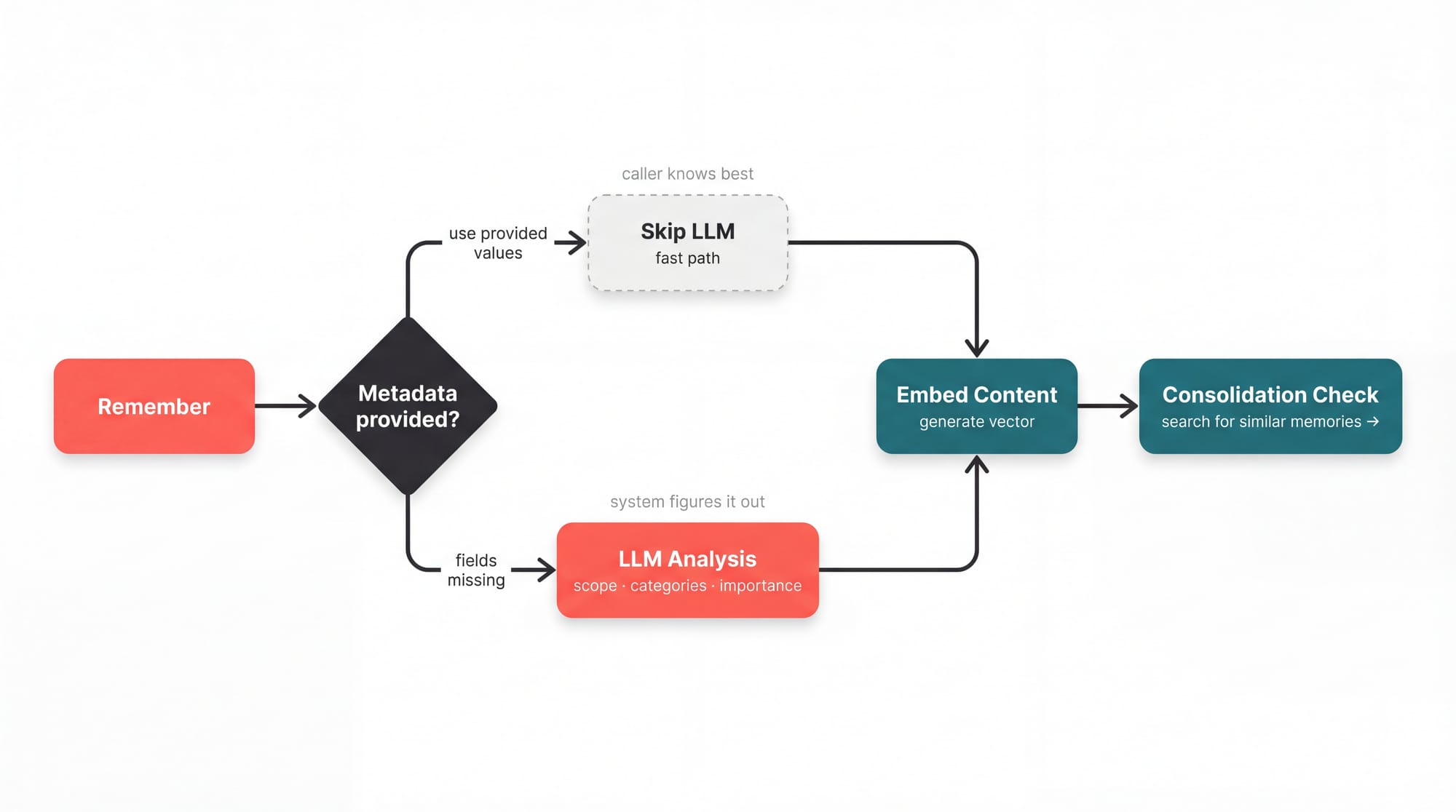
Every remember() call also triggers a similarity search against existing memories, similarly as how humans do as you learn new things and find ways to cluster than together and even infer new information based on that.
Walk through the example:
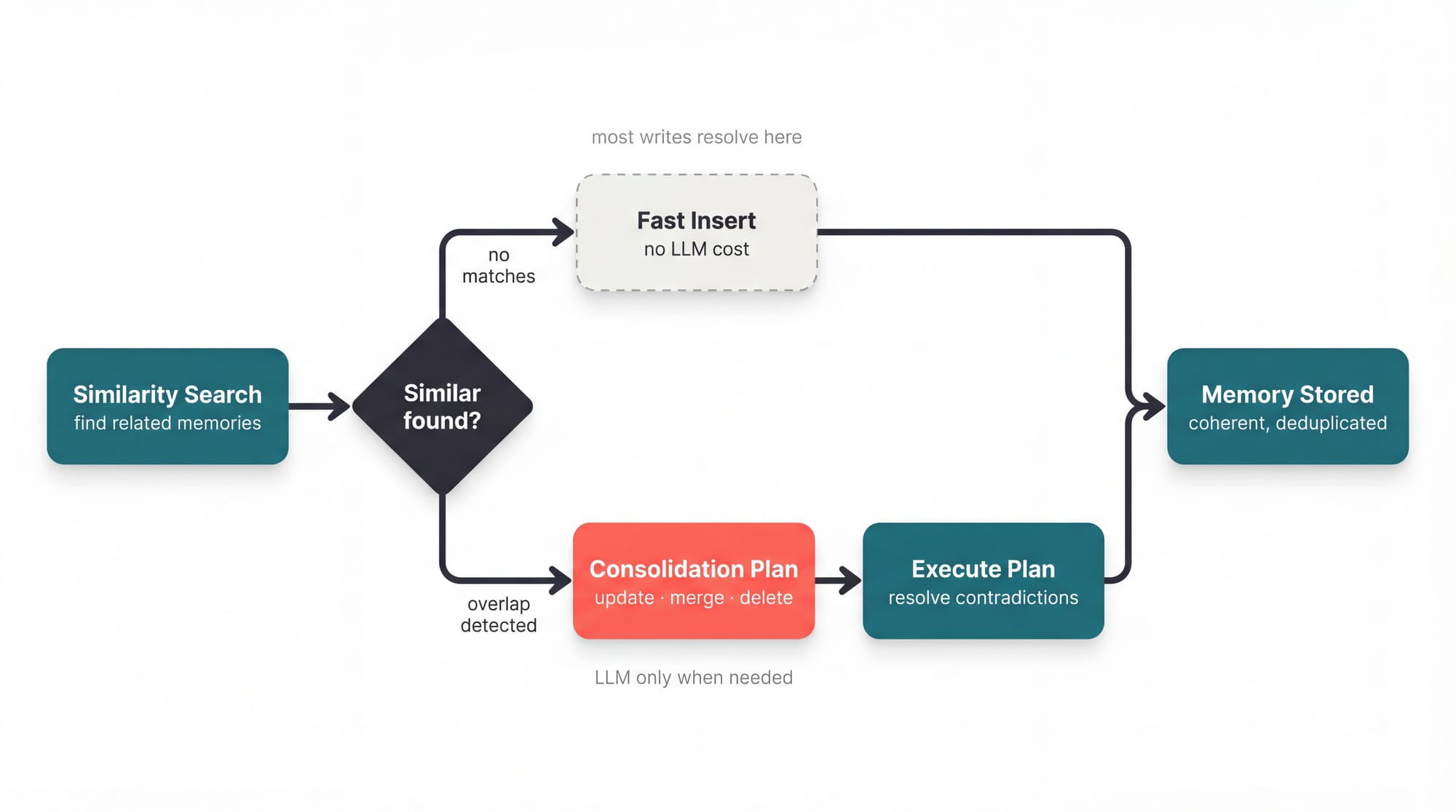
You stored "We use PostgreSQL for the user database" last month. Now you're storing "We migrated to MySQL last week."
In other systems, both coexist and retrieval is a coin flip. In Cognitive Memory, the consolidation logic detects the similarity, recognizes the contradiction, and produces a plan: update the old record's content, preserve the migration context, delete the stale fact, so you get one coherent memory instead of two competing ones.
In CrewAI's memory, the consolidation step in the encoding flow detects the similarity, recognizes the contradiction, and produces a plan: update the old record's content, preserve the migration context, delete the stale fact, so you end up with one coherent memory instead of two competing ones.
Recall Agentic System
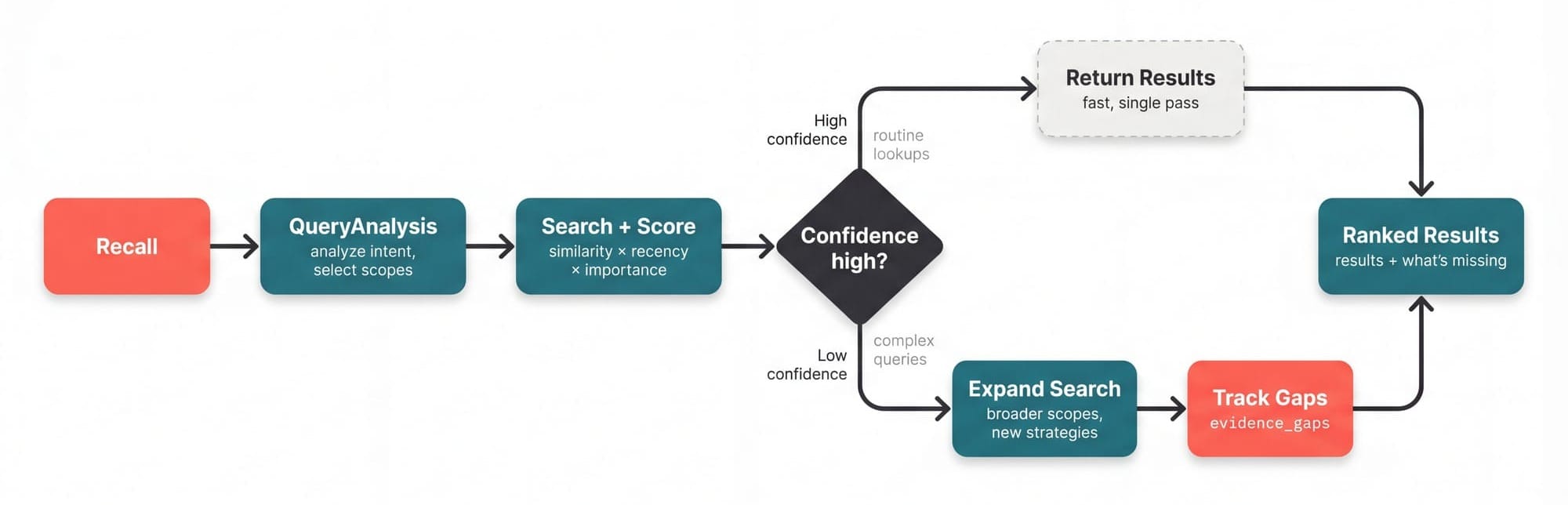
Recall Flow does two things other systems don't: it scores results by what actually matters, and it knows when to search deeper.
Composite scoring blends three signals instead of just one, similarity, recency and importance, applying a specific weight for each (that you have full control to customize as well on the access layer of the memory, while the memory itself remains intact)
score = (similarity × w_sim) + (recency × w_rec) + (importance × w_imp)
This is why a critical architecture decision from six months ago outranks a trivial note from yesterday that happens to mention "database." Pure vector search returns the trivial note. But a cognitive composite scoring returns the decision.
It analyzes the query, selects which scopes to search, retrieves candidates, then evaluates its own confidence. If needed it will search deeper, broader the scopes, and try different strategies, all that while keeping tracks of what's missing as evidence_gaps.
Atomic Memories
Agents don't think in clean, individual facts, like a research agent returns a 500 word summary, meanwhile an analyst produces a report covering six topic, if you store any of that as one memory, you're back to the blob problem and retrieval pulls everything when you need one fact, and consolidation can't resolve a contradiction buried inside a paragraph.
As part of our new Cognitive Memory there is the ability to extract memories from agentic executions and bigger blobs of text, extract_memories() decomposes raw output into self-contained atomic facts:
raw = """After reviewing the infrastructure options, the team recommends PostgreSQL for the user database due to its JSONB support. Estimated cost is $2,400/month on RDS. The compliance team flagged that all user data must stay in EU regions. DevOps prefers managed services over self-hosted to reduce on-call burden.""" facts = memory.extract_memories(raw) # → "Team recommends PostgreSQL for user database due to JSONB support" # → "Estimated database cost is $2,400/month on RDS" # → "Compliance requires all user data to remain in EU regions" # → "DevOps prefers managed services over self-hosted"
In this example above, each extracted fact enters the full cognitive pipeline independently, the database recommendation gets encoded with high importance under /infrastructure/database while the compliance requirement gets its own scope under /compliance. So later when you store "We're switching to MySQL," consolidation resolves against the PostgreSQL recommendation specifically, not against a blob that also mentions cost estimates and team preferences.
This is also what powers automatic memory in Crews. When an agent completes a task with memory=True, the system runs extraction on the output, decomposes it into atomic facts, and feeds each one through encoding and consolidation. You write one flag and the system handles everything for you.
What This Unlocks
The real shift isn't that your agents remember things, it's that your Agentic Systems compound.
Without memory, every run is independent, roughly same cost, same latency, same discovery process, same ceiling but using Cognitive Memory, each run makes the next one better, an agent that's processed a thousand customer tickets doesn't just have a thousand memories. It has consolidated patterns, resolved contradictions, built a hierarchy of what matters, so run 1,001 is fundamentally different from run 1, it's faster, cheaper, more reliable, because the system has learned and evolved.
This also drastically changes what you can build:
Human-in-the-loop systems that learn from corrections. A Flow with @human_feedback(learn=True) doesn't just collect approvals, it distills each correction into a generalizable lesson and stores it in memory. Next run, the system recalls those lessons and applies them before the human even sees the output. The reviewer who used to rewrite every draft now just approves, because the system learned what they care about.
Research systems that accumulate expertise. A research Flow that runs weekly doesn't start from scratch each time, it recalls what it found before, identifies what's changed, and focuses on the delta and after a few executions, it's not doing research, it's maintaining a living knowledge base that gets more refined with every cycle.
Multi-agent teams with shared understanding. Agents share a memory but recall differently, a planning agent weights importance while an execution agent weights recency, so you find yourself with same knowledge but being able to tap into it through different lenses. Like a team where the architect remembers principles and the engineer remembers what shipped last sprint.
Systems that shift from execution to exploration. This is probably the biggest unlock: Stateless agents can only execute, given input, produce output. Agents with cognitive memory can explore, try an approach, remember what worked, refine on the next run. They develop strategies. They get better at getting better.
And every cognitive operation described in this post, encoding, consolidation, adaptive recall, is itself a CrewAI Flow. The memory system is an agentic system built on the same platform you use to build yours. It's so great we get to use our own product to build our product, proof that the architecture holds when the problem is hard enough to demand it.
Try it yourself!
As simple as:
pip install crewaiand then you can quickly try with one single agent in a python shell:
from crewai import Agent agent = Agent( role="Technical Advisor", goal="Help the team make infrastructure decisions", backstory="Senior engineer with deep knowledge of agentic systems", memory=True ) agent.kickoff("what are the benefits of using CrewAI to build agentic systems?")
after that you can actually navigate all memories generated by running, in the same directory:
crewai memory
Comments ()